Rakesh Chada's Blog Deep Learning & Natural Language Processing
The unreasonable effectiveness of one neuron
(All my experiments and visualizations can be viewed in this jupyter notebook).
I recently came across a research paper (Radford et al.,) that quite fascinated me. The authors discovered that a single neuron captured the sentiment of an entire piece of text. They go even further and show that it performed very well on sentiment classification tasks even with zero supervision. What not! They even generate coherent pieces of text by fixing the neuron’s value.
This isn’t the first time someone discovered such interpretable neurons though. Karpathy et al.,, for instance, discovered neurons that activated inside quotes, if statements in a code block etc. This was explained in detail in this great blog post. In fact that post inspired the name for this post of mine :) However, sentiment is a high-level representation. It has more to do with a deeper understanding of the semantics of the text and not just its syntactical structure. The fact that a single neuron captured the whole sentiment is mind boggling. It means that a single floating point number is all it takes to classify the sentiment of a paragraph. How fascinating is that?!
I personally wanted to explore this in much detail. Thankfully, the authors have open sourced the model they have trained for approximately one month (!) along with some of their code base. I added the sentiment neuron heatmap visualization to it and made some other modifications. I chose Yelp reviews binary dataset introduced in Zhang et al., for the analysis. There are ~600,000 reviews in total.
Language Model
It all starts from the character-level language modeling task. The goal is to predict one character at a time in a piece of text. An advantage to character-level modeling in contrast to word-level is its inherent ability to capture out-of-vocabulary words. The authors trained a multiplicative LSTM model with 4096 units. Each character was encoded into a 64 dimensional vector and the LSTM operates on batches of 64 characters at a time. They have used the Amazon reviews dataset with ~82 million product reviews.
Sentiment Neuron Discovery
The first question that intrigued me was - How did the authors discover this sentiment neuron in the first place? I mean, there were like 4096 neurons in the output layer. Did they visualize each one of those trying to find some patterns? Maybe not. But if you read the paper carefully, you would find that they trained linear models on top of those 4096 neurons using L1 regularization. Given that there’s a model with 4096 features, discovering this specific feature would then boil down to the matter of feature contributions (weights). If a single neuron solved almost the entire classification task, then the contribution from it should be very high and noticeable.
Let’s see if that is the case for our sentiment neuron. This is the graph of feature contributions that I produced by training on Yelp dataset for sentiment classification.
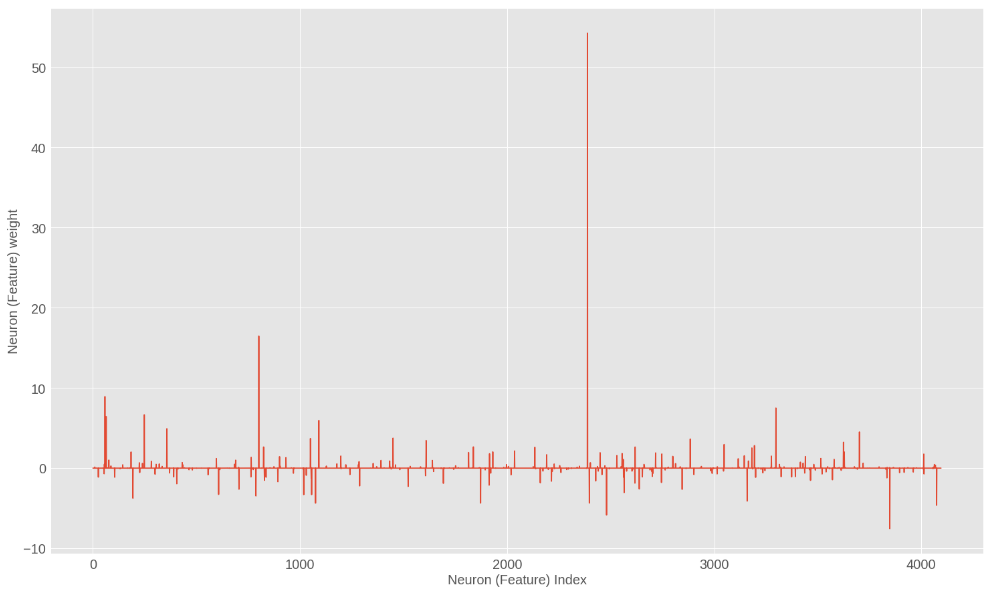 Feature importances with l1 regularization
Feature importances with l1 regularization
Wow! Indeed there is a single feature with a large weight. It must be the sentiment neuron. In fact, we can even get its index among the list of 4096 neurons. If you look at the notebook, you will see that it’s the index 2388. There are also a few other neurons that have relatively higher contributions. We will look at them in the end.
Unsupervised Learning
Now that we have discovered sentiment neuron had a great impact on the final sentiment, it would be interesting to see the effect of training data size in its learning capacity. The authors have done this experiment. They start with zero training data and gradually increase it till the performance hits a limit. This led to an intriguing discovery. Even with zero labeled data, the sentiment neuron was able to predict the sentiment with great accuracy! Unsupervised Learning to the great effect! The model was trained on a language modeling task without using any hand labeled data. One of the features in that model is then used to make a prediction on another task (sentiment classification) without any supervised training. This is also analogous to a typical transfer learning setup which is a common technique in Computer Vision tasks.
Furthermore, the performance hits the upper limit quite soon (10-100 examples depending on task). This means that having a million hand labeled examples has the same effect on model’s performance as having a hundred examples. One could save a lot of labeling effort and cost if this pattern was discovered before!
Coming to our Yelp classification task, I tried the unsupervised classification on the dataset by using a threshold on sentiment neuron’s value. As the output is fed through a tanh gate, I predict the positive class if the output is positive and negative if the output is negative. Without any training, this gave me an accuracy of ~93.67% on the task. That is quite amazing!
Visualization of the sentiment neuron
A good way to gain intuition on what’s going on under the hood is to visualize stuff. Visualization can be challenging for LSTMs but fortunately we just have a single neuron to track in this case. Karpathy had done some fantastic work on visualizing RNNs. Following similar ideas, I built some handy python functions that help visualize the sentiment neuron. As this is a character level model, we can track the values of sentiment neuron as it processes each character. These values can then be represented as a heatmap of sentiments. One such heatmap can be seen below:
![]() Sentiment Heat map for a review
Sentiment Heat map for a review
You can observe that the sentiment neuron was tracking the state accurately without getting affected by one-off negative words like expensive or disappoint.
Here’s another one for a negative review:
![]()
It’s really nice how the neuron changes its state in the negative direction on seeing phrases like not a good, slow, loud etc. Furthermore, the overall sentiment didn’t get affected despite the positive sounding phrase town with some good pie. (Attention mechanism anyone?)
Great! How does it perform on larger pieces of text?
![]()
![]()
That’s fantastic! It managed to capture all the variations in sentiment quite accurately despite the huge length of the text. Lengthy texts are something Recurrent Neural Networks usually struggle at!
Alright, we’ve now gained some intuition on how the sentiment neuron was able to successfully process the text. It will be equally interesting to understand what’s going on in the failure cases.
Here’s an example:

Hmm interesting! There are a couple of things going on in here. Firstly there is sarcasm at the beginning of the review. The neuron couldn’t capture that and treated it as a positive sentiment. And then there were clear negative comments which the neuron successfully captured. And at the end, the review goes on praising another restaurant. The sentiment is technically positive for this part but just that it is associated to another restaurant. Overall, I kinda understand how this is a tough case for the sentiment neuron.
There were a few cases where it’s not clear what is going on with the neuron though. Let’s look at the below example.
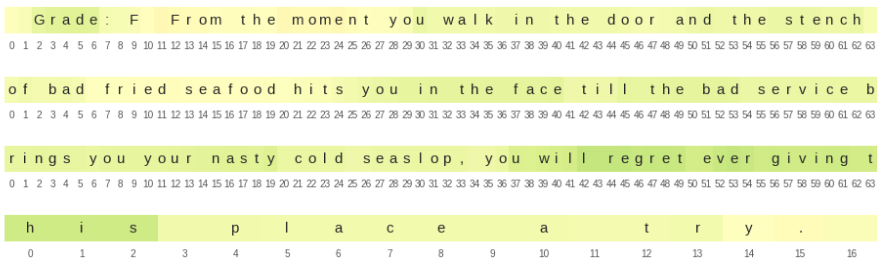
The sentiment somehow always stays in the positive zone despite the clear presence of negative phrases!
End of the sentence updates
If you look at all the plots, you see one common pattern. The value of the sentiment neuron gets a major update at the end of the sentence (typically after seeing a “.”). This means the neuron was kind of breaking the entire paragraph into a list of sentences and updating the sentiment values after processing each sentence. That is quite a fascinating result for a character level model!
Sentiment Shifts
It might be informative to also look at how the sentiment values shift in magnitude across the span of the text. The below plot is one such way of analyzing that.
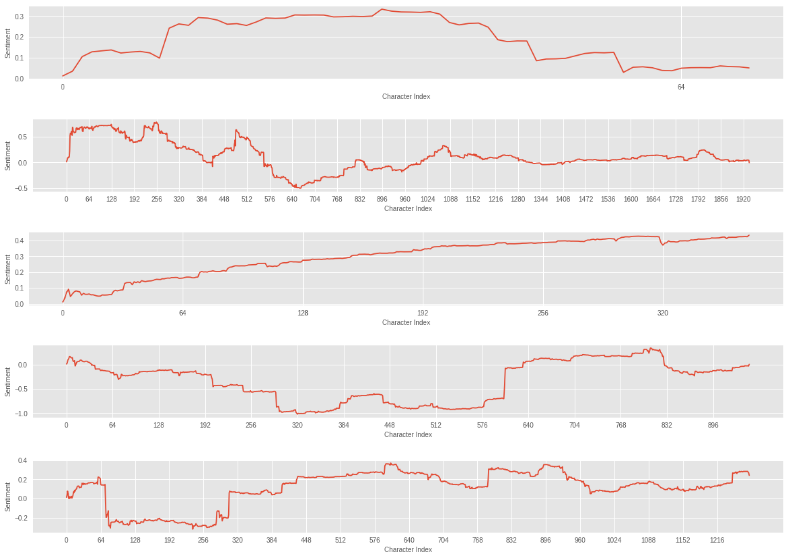
I was looking for some patterns in the shifts that are correlated with the relative position in the sentence. But there’s no clear pattern that stood out across any of those plots.
Effect of review length
We have previously seen that the neuron was able to handle even large reviews pretty well. Let’s now try to visualize the distribution of lengths in cases where sentiment neuron succeeded and failed. If length affected the performance, this plot should clearly show that.
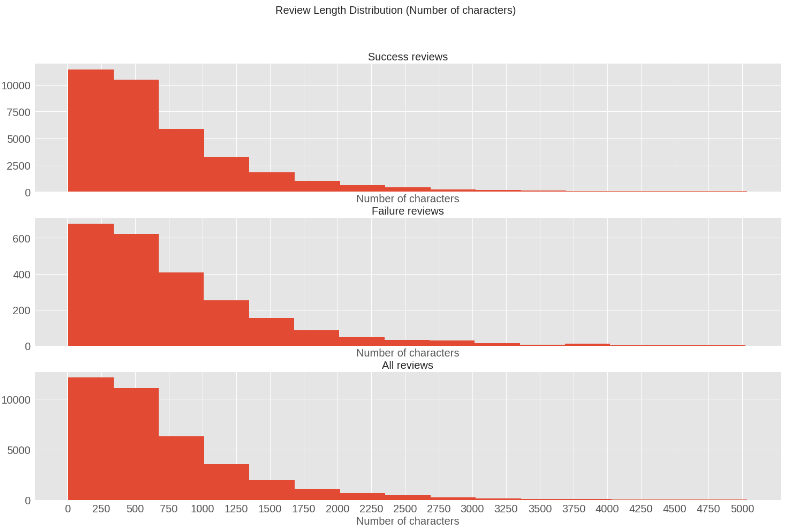
All the distributions (success and failure) look identical to the true distribution. This means that review length has no correlation with the performance of the neuron. That is quite some news!
Other important neurons
We noticed a few other neurons with higher contributions when we visualized the feature contributions. I tried tracking their states across reviews just like how I did for the sentiment neurons. Below is one such visualization.
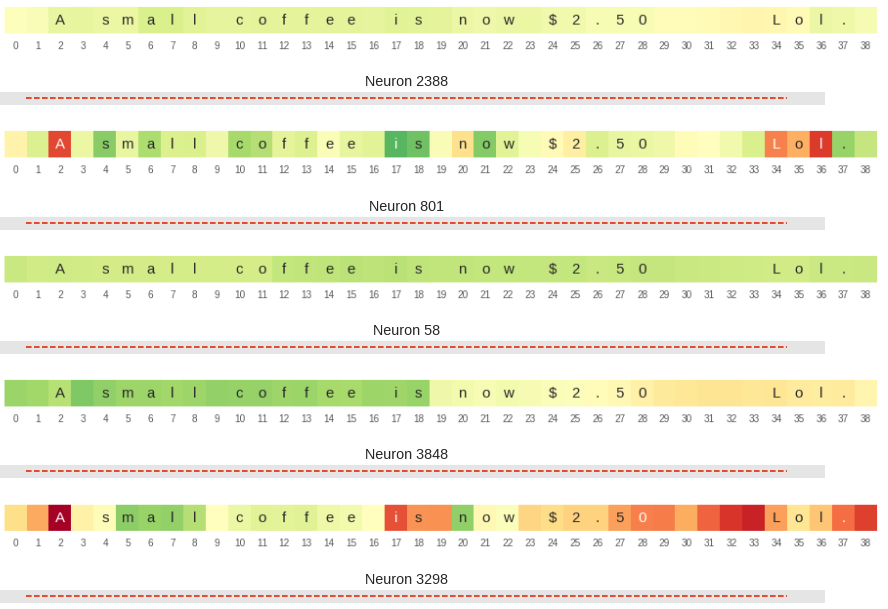 I couldn’t spot any obvious patterns though. You can refer to the notebook for more such visualizations. Feel free to play around and please do post if you find any interesting patterns.
I couldn’t spot any obvious patterns though. You can refer to the notebook for more such visualizations. Feel free to play around and please do post if you find any interesting patterns.
Supervised Training
We have seen how the sentiment neuron performed with zero supervision. I’ve also tried training the model on the entire yelp dataset. The best linear model (Logistic regression with l2 regularization and 0.001 learning rate) gave me ~94.86% accuracy. This is just ~1% improvement over unsupervised training with just the sentiment neuron. This is consistent with the authors’ claim that additional supervision helps only to a certain extent and the performance hits the limit very soon.
Text Generation
The neural network we were talking about all through was trained to predict next characters. So it wouldn’t be justice if we don’t generate some samples out of it :)!
Here’s what it generated when asked to start with “Hmm”.
Hmm what a waste of film not to mention a Marilyn movie for nothing.
Hmm that wasn’t bad!
The fun part was to generate samples by fixing the value of the sentiment neuron. Here are some generated samples.
- Sentiment = 1.0 and Starting Phrase = “This is” =>
This is a great album with a quality history of the group. - Sentiment = -1.0 and Starting Phrase = “It might” =>
It might have been good but I found myself skipping pages to get to the end.
I tried tricking it by providing phrases like “I can’t” as the starting phrase but fixing the sentiment to be positive. But it still did quite well like below.
- Sentiment = 1.0 =>
I can't wait to try the other flavors - and I have a ton of them on hand just in case one should have gone out for a trip or need a "big new place" and they are delicious. - Sentiment = -1.0 =>
I can't believe I bought this book.
It’s nice that the phrases generated were coherent, human like and also match the expected sentiment.
That said, there have been occasions where the generated text didn’t quite match the sentiment.
- Sentiment = -1.0 and Starting Phrase = “Great” =>
Great DVD with the original production leaving good video and audio quality.
The interesting thing about generation is that it can also be seen as a way to gain intuition of individual neurons. For this reason, I tried generating text by fixing values of other important neurons. For instance, fixing the value of neuron 801 to -1.0 generated this text.
This is the greatest movie ever! Ever since my parents had watched it back in the 80s, I always watched it.
There seems to be some correlation of it (neuron 801) with the sentiment.
It’s a fun exercise to fix values of different (even multiple ones together) and look at the generated texts. You can look at the notebook for such generated samples.
What next?
We’ve seen several intriguing things. These results should be a great motivating factor to put more research into language modeling and pre-training/transfer learning in NLP. Word vectors (word2vec, GloVe etc) are usually the only sort of pre-trained outputs currently used in Deep Learning NLP tasks. I am also excited about the results where one scales up/scales down the domain of datasets and do similar analyses. For instance, one of the hypotheses (made by authors) for such discrete presence of sentiment neuron is that sentiment is a strong predictive feature for language modeling of reviews. So could we discover such discrete & interpretable neurons by manually controlling the distribution of our training datasets? As an example, can we discover topic neurons by making our training data to be news corpus of different topics? Overall the idea here is to make the training data to be very domain/task specific and see if we can recover any interpretable neurons through language modeling. This can be done on multiple domains/tasks.
Another approach is to scale up the domains. This means you include as much data (from several domains) as possible in your training set, do the similar analyses and see if you can discover anything interpretable. There are many publicly available datasets to do such analyses.
It would also be interesting to see how word-level language modeling compares to the character-level language modeling for this task.
There are endless possibilities and I am excited for any future work that’s related to this!
PS: I am continuously trying to ramp up my Neural Network knowledge and I think implementing stuff is a great way to learn. I am doing this as a sequence of different tasks. If you too are interested, you can follow this repository!
Written on May 12th, 2017 by Rakesh Chada