Rakesh Chada's Blog Deep Learning & Natural Language Processing
Unsupervised NLU task learning via GPT-2
The language model GPT-2 from OpenAI is one of the most coherent generative models for text out there. While its generation capabilities are impressive, it’s ability to zero-shot perform some of the Natural Language Understanding (NLU) tasks seems even more fascinating to me! In this blog post, I briefly highlight some of those capabilities and deep dive on one such fun use-case of converting singular nouns in english to their plural counterparts and vice-versa1.
Zero-shot NLU with language models
One of the first examples of zero/few shot learning an NLU task through language modeling was that of the Sentiment Neuron. A single neuron unit learnt to capture the sentiment of the reviews when trained on a language modeling task on a corpus of reviews. Post that, there has been an emergence of several language models and GPT-2 is one of them that demonstrated great generation and zero-shot tasking capabilities. A language model (in text domain) gives us a probability for a sequence of words. For it to output the result of a task of our interest, the model needs to be conditioned on a few examples demonstrating what the task is. This is usually done by adding a prompt to the inputs of the language model. For example, as demonstrated in the original GPT-2 paper, a prompt of <english sentence 1> = <french sentence 1>. <english sentence 2> = <french sentence 2>...<english sentence n> = makes the language model output french translation for <english sentence n>.
This prompt-based conditioning gives us a very handy way to guide the model to perform the task of interest. It’s worth noting that there is no additional supervision signal involved.
Another use-case that highlights this capability is the classic NLU task of Person Name Recognition. In the below example image2, we provide the model a prompt containing four examples to help model infer the task. The task is to extract all person names in the provided sentence. You can see that the model3 rightly extracts all person names for the final two sentences.
 Prediction (Text highlighted in grey) from GPT-2 large model
Prediction (Text highlighted in grey) from GPT-2 large model
However, it is not perfect. It some times misses a person name, produces duplicates or identifies non-persons as persons. The image below shows one such scenario where it missed a person name (“Veturi Sundararama Murthy”) in the last sentence.
 Prediction (Text highlighted in grey) from GPT-2 large model
Prediction (Text highlighted in grey) from GPT-2 large model
The output is (reasonably) pretty sensitive to the prompt. So it usually takes a bit of manual engineering to build the prompt that leads the model to produce the desired output. Nevertheless, it’s fascinating that we were able to get decent NER outputs in a completely unsupervised fashion.
The convenient web interface of write with transformer gives us a great way to experiment with and learn about several GPT-2 capabilities/incapabilities. Below are a few examples4 of different learning tasks.
Question Answering style task
The below image demonstrates some of GPT-2’s capabilities to answer specific questions related to the prompt. Specifically, it seems to identify and differentiate the dog breed and color to a good extent.

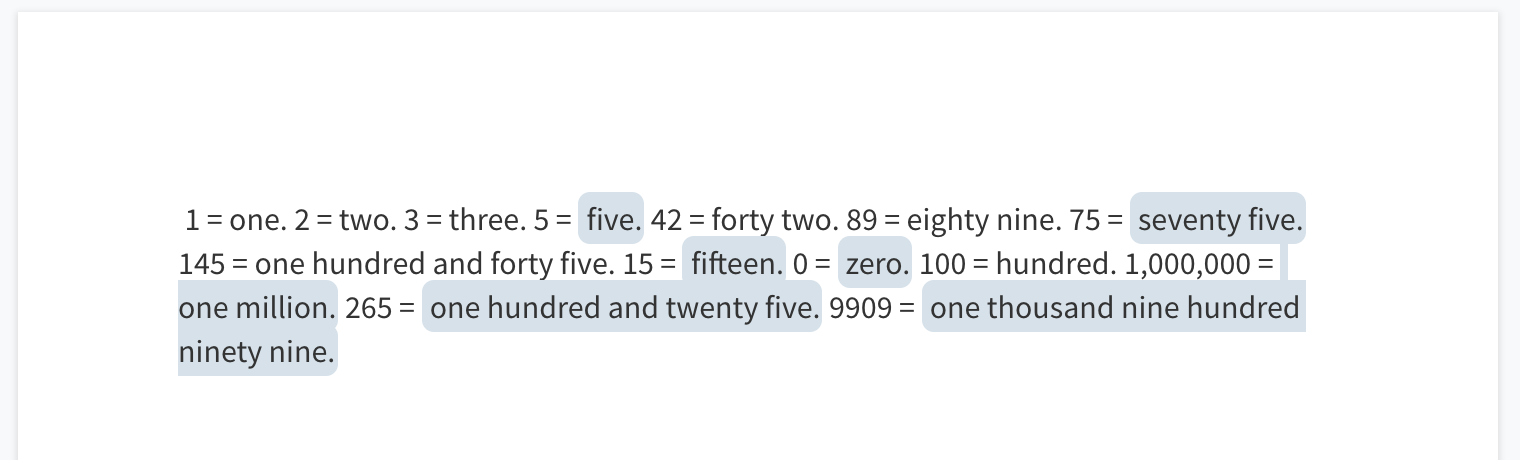
Integer to words
The task here is to convert a given integer to english words. It’d be very interesting if the model learnt to do this accurately. Below image shows mixed results of the model on this task. It’s exciting to see it correctly convert some integers. At the same time, it produces inaccurate results in other cases.
Learning arithmetic functions
The task here is to learn the right function to apply and then produce the resulting output. Below image shows that the model doesn’t show much success on the multiplication task with the given prompt (although there are again some signs of success)

With that context, let’s now deep-dive on one use-case.
Singular-Plural conversion
The task here is to produce a plural counter-part given a singular common noun in English. There are several rules (and exceptions) that are involved in pluralizing a common noun. Deterministic libraries that use these rules and help us get plurals for any english word do exist. But it also seemed like an interesting Machine Learning problem.
How would an unsupervised approach using GPT-2 fare for this task?
To get results using GPT-2, the model5 needs to “understand” that plural generation is the desired task. This is done (as in the other use-cases) by conditioning on an illustrative prompt. After some manual experimentation, the below prompt seemed to have been sufficient to help model infer the task ({noun} is the noun in question).
mat : mats . analysis : analyses . advance : advances . criterion : criteria . actress : actresses . view : views . kind : kinds . art : arts . effort : efforts . lack : lacks . {noun} :
Plurals of certain nouns are the same nouns. So I also include few such examples in the prompt.
Evaluation Data
Firstly, I manually tried generating plurals for a few random nouns that came to mind and the model seemed very effective in producing plurals for those. Then, I built a golden evaluation dataset of nouns to get a general idea of its performance. I extracted common nouns from here and here. And I used wordhippo to extract the gold plurals for the extracted nouns. This resulted in an evaluation dataset of 1016 nouns. Now, given the above prompt, the GPT-2 model was asked to generate next 10 tokens. The output was split at the period symbol to extract the plural.
Results
On the evaluation dataset, the model had an accuracy of atleast6 94%. That’s astonishing!
Looking at the results, it seemed that the model accurately predicted plurals even for several exception cases (such as “ox”, “calf”, “foot”, “person”). It also seemed to know when to output the same noun as the plural. Below table shows some of those compelling results.
| Word | Predicted Plural |
|---|---|
| bacterium | bacteria |
| brother-in-law | brothers-in-law |
| ox | oxen |
| knife | knives |
| person | people |
| labour | labour |
| axis | axes |
| miss | misses |
| criterion | criteria |
| foot | feet |
| mouse | mice |
| boogeyman | boogeymen |
| parliament | parliament |
And the below table shows some examples where the model predictions were wrong.
| Word | Predicted Plural |
|---|---|
| staff | staff |
| example | example |
| afternoon | afternoon |
| sky | sky |
| zero | zero |
| sheep | sheeps |
The reverse task: Plural to Singular
So, the model seemed quite effective in producing a plural for a given common noun. How about the reverse? Can it produce the corresponding singular given a plural?
The results were quite sensitive to the prompt. When the model was provided the singular version of the same prompt as above, which is, mats : mat . analyses : analysis . advances : advance . criteria : criterion . actresses : actress . views : view . kinds : kind . arts : art . efforts : effort . lacks : lack . {plural} :, it had an accuracy of ~58%. However, if I modify the prompt to below, it has a much higher accuracy of ~90%.
mats : mat . advances : advance . actresses : actress . criteria : criterion . views : view . kinds : kind . arts : art . efforts : effort . ways : way . countries : country . women : woman . wives : wife . courses : course . {plural} :
There are probably other prompts too that I didn’t experiment with that would lead to higher accuracies. Nevertheless, it seems like the model is also effective at singularizing plural nouns!
Overall, it was interesting to see some of the zero-shot capabilities of the GPT-2 model. There’s still a big gap in the performance especially when compared to some supervised models on specific tasks. But that gap is slowly shrinking as the research in un/self-supervised learning is gaining pace! Exciting times ahead!
-
The code for the singular<->plural experiment is available here ↩
-
I use Hugging Face’s awesome write with transformer tool for the visuals. ↩
-
The model used here is the 774 M parameter GPT-2 large ↩
-
The model used here is the 1.5 billion parameter GPT2-xlarge ↩
-
The model used here is GPT-2 large. I tried running the GPT2-xlarge on the plural prediction task but the results weren’t significantly different. ↩
-
I say “atleast” because some of the errors among the remaining 6% of the cases seemed to be due to the lack of enough context. ↩